
64 bytes and a ROP chain – A journey through nftables – Part 1
The purpose of this article is to dive into the process of vulnerability research in the Linux kernel through my experience that led to the finding of CVE-2023-0179 and a fully functional Local Privilege Escalation (LPE).
By the end of this post, the reader should be more comfortable interacting with the nftables component and approaching the new mitigations encountered while exploiting the kernel stack from the network context.
1. Context
As a fresh X user indefinitely scrolling through my feed, one day I noticed a tweet about a Netfilter Use-after-Free vulnerability. Not being at all familiar with Linux exploitation, I couldn’t understand much at first, but it reminded me of some concepts I used to study for my thesis, such as kalloc zones and mach_msg spraying on iOS, which got me curious enough to explore even more writeups.
A couple of CVEs later I started noticing an emerging (and perhaps worrying) pattern: Netfilter bugs had been significantly increasing in the last months.
During my initial reads I ran into an awesome article from David Bouman titled How The Tables Have Turned: An analysis of two new Linux vulnerabilities in nf_tables describing the internals of nftables, a Netfilter component and newer version of iptables, in great depth. By the way, I highly suggest reading Sections 1 through 3 to become familiar with the terminology before continuing.
As the subsystem internals made more sense, I started appreciating Linux kernel exploitation more and more, and decided to give myself the challenge to look for a new CVE in the nftables system in a relatively short timeframe.
2. Key aspects of nftables
Touching on the most relevant concepts of nftables, it’s worth introducing only the key elements:
- NFT tables define the traffic class to be processed (IP(v6), ARP, BRIDGE, NETDEV);
- NFT chains define at what point in the network path to process traffic (before/after/while routing);
- NFT rules: lists of expressions that decide whether to accept traffic or drop it.
In programming terms, rules can be seen as instructions and expressions are the single statements that compose them. Expressions can be of different types, and they’re collected inside the net/netfilter directory of the Linux tree, each file starting with the “nft_” prefix.
Each expression has a function table that groups several functions to be executed at a particular point in the workflow, the most important ones being .init, invoked when the rule is created, and .eval, called at runtime during rule evaluation.
Since rules and expressions can be chained together to reach a unique verdict, they have to store their state somewhere. NFT registers are temporary memory locations used to store such data.
For instance, nft_immediate stores a user-controlled immediate value into an arbitrary register, while nft_payload extracts data directly from the received socket buffer.
Registers can be referenced with a 4-byte granularity (NFT_REG32_00 through NFT_REG32_15) or with the legacy option of 16 bytes each (NFT_REG_1 through NFT_REG_4).
But what do tables, chains and rules actually look like from userland?
# nft list ruleset
table inet my_table {
chain my_chain {
type filter hook input priority filter; policy drop;
tcp dport http accept
}
}
This specific table monitors all IPv4 and IPv6 traffic. The only present chain is of the filter type, which must decide whether to keep packets or drop them, it’s installed at the input level, where traffic has already been routed to the current host and is looking for the next hop, and the default verdict is to drop the packet if the other rules haven’t concluded otherwise.
The rule above is translated into different expressions that carry out the following tasks:
- Save the transport header to a register;
- Make sure it’s a TCP header;
- Save the TCP destination port to a register;
- Emit the NF_ACCEPT verdict if the register contains the value 80 (HTTP port).
Since David’s article already contains all the architectural details, I’ll just move over to the relevant aspects.
2.1 Introducing Sets and Maps
One of the advantages of nftables over iptables is the possibility to match a certain field with multiple values. For instance, if we wanted to only accept traffic directed to the HTTP and HTTPS protocols, we could implement the following rule:
nft add rule ip4 filter input tcp dport {http, https} acceptIn this case, HTTP and HTTPS internally belong to an “anonymous set” that carries the same lifetime as the rule bound to it. When a rule is deleted, any associated set is destroyed too.
In order to make a set persistent (aka “named set”), we can just give it a name, type and values:
nft add set filter AllowedProto { type inet_proto\; flags constant\;}
nft add element filter AllowedProto { https, https }
While this type of set is only useful to match against a list/range of values, nftables also provides maps, an evolution of sets behaving like the hash map data structure. One of their use cases, as mentioned in the wiki, is to pick a destination host based on the packet’s destination port:
nft add map nat porttoip { type inet_service: ipv4_addr\; }
nft add element nat porttoip { 80 : 192.168.1.100, 8888 : 192.168.1.101 }
From a programmer’s point of view, registers are like local variables, only existing in the current chain, and sets/maps are global variables persisting over consecutive chain evaluations.
2.2 Programming with nftables
Finding a potential security issue in the Linux codebase is pointless if we can’t also define a procedure to trigger it and reproduce it quite reliably. That’s why, before digging into the code, I wanted to make sure I had all the necessary tools to programmatically interact with nftables just as if I were sending commands over the terminal.
We already know that we can use the netlink interface to send messages to the subsystem via an AF_NETLINK socket but, if we want to approach nftables at a higher level, the libnftnl project contains several examples showing how to interact with its components: we can thus send create, update and delete requests to all the previously mentioned elements, and libnftnl will take care of the implementation specifics.
For this particular project, I decided to start by examining the CVE-2022-1015 exploit source since it’s based on libnftnl and implements the most repetitive tasks such as building and sending batch requests to the netlink socket. This project also comes with functions to add expressions to rules, at least the most important ones, which makes building rules really handy.
3. Scraping the attack surface
To keep things simple, I decided that I would start by auditing the expression operations, which are invoked at different times in the workflow. Let’s take the nft_immediate expression as an example:
static const struct nft_expr_ops nft_payload_ops = {
.type = &nft_payload_type,
.size = NFT_EXPR_SIZE(sizeof(struct nft_payload)),
.eval = nft_payload_eval,
.init = nft_payload_init,
.dump = nft_payload_dump,
.reduce = nft_payload_reduce,
.offload = nft_payload_offload,
};
Besides eval and init, which we’ve already touched on, there are a couple other candidates to keep in mind:
- dump: reads the expression parameters and packs them into an skb. As a read-only operation, it represents an attractive attack surface for infoleaks rather than memory corruptions.
- reduce: I couldn’t find any reference to this function call, which shied me away from it.
- offload: adds support for nft_payload expression in case Flowtables are being used with hardware offload. This one definitely adds some complexity and deserves more attention in future research, although specific NIC hardware is required to reach the attack surface.
As my first research target, I ended up sticking with the same ops I started with, init and eval.
3.1 Previous vulnerabilities
We now know where to look for suspicious code, but what are we exactly looking for?
The netfilter bugs I was reading about definitely influenced the vulnerability classes in my scope:
CVE-2022-1015
/* net/netfilter/nf_tables_api.c */
static int nft_validate_register_load(enum nft_registers reg, unsigned int len)
{
/* We can never read from the verdict register,
* so bail out if the index is 0,1,2,3 */
if (reg < NFT_REG_1 * NFT_REG_SIZE / NFT_REG32_SIZE)
return -EINVAL;
/* Invalid operation, bail out */
if (len == 0)
return -EINVAL;
/* Integer overflow allows bypassing the check */
if (reg * NFT_REG32_SIZE + len > sizeof_field(struct nft_regs, data))
return -ERANGE;
return 0;
}
int nft_parse_register_load(const struct nlattr *attr, u8 *sreg, u32 len)
{
...
err = nft_validate_register_load(reg, len);
if (err < 0)
return err;
/* the 8 LSB from reg are written to sreg, which can be used as an index
* for read and write operations in some expressions */
*sreg = reg;
return 0;
}
I also had a look at different subsystems, such as TIPC.
CVE-2022-0435
/* net/tipc/monitor.c */
void tipc_mon_rcv(struct net *net, void *data, u16 dlen, u32 addr,
struct tipc_mon_state *state, int bearer_id)
{
...
struct tipc_mon_domain *arrv_dom = data;
struct tipc_mon_domain dom_bef;
...
/* doesn't check for maximum new_member_cnt */
if (dlen < dom_rec_len(arrv_dom, 0))
return;
if (dlen != dom_rec_len(arrv_dom, new_member_cnt))
return;
if (dlen < new_dlen || arrv_dlen != new_dlen)
return;
...
/* Drop duplicate unless we are waiting for a probe response */
if (!more(new_gen, state->peer_gen) && !probing)
return;
...
/* Cache current domain record for later use */
dom_bef.member_cnt = 0;
dom = peer->domain;
/* memcpy with out of bounds domain record */
if (dom)
memcpy(&dom_bef, dom, dom->len);
A common pattern can be derived from these samples: if we can pass the sanity checks on a certain boundary, either via integer overflow or incorrect logic, then we can reach a write primitive which will write data out of bounds. In other words, typical buffer overflows can still be interesting!
Here is the structure of the ideal vulnerable code chunk: one or more if statements followed by a write instruction such as memcpy, memset, or simply *x = y inside all the eval and init operations of the net/netfilter/nft_*.c files.
3.2 Spotting a new bug
At this point, I downloaded the latest stable Linux release from The Linux Kernel Archives, which was 6.1.6 at the time, opened it up in my IDE (sadly not vim) and started browsing around.
I initially tried with regular expressions but I soon found it too difficult to exclude the unwanted sources and to match a write primitive with its boundary checks, plus the results were often overwhelming. Thus I moved on to the good old manual auditing strategy.
For context, this is how quickly a regex can become too complex:
if\s*\(\s*(\w+\s*[+\-*/]\s*\w+)\s*(==|!=|>|<|>=|<=)\s*(\w+\s*[+\-*/]\s*\w+)\s*\)\s*\{
Turns out that semantic analysis engines such as CodeQL and Weggli would have done a much better job, I will show how they can be used to search for similar bugs in a later article.
While exploring the nft_payload_eval function, I spotted an interesting occurrence:
/* net/netfilter/nft_payload.c */
switch (priv->base) {
case NFT_PAYLOAD_LL_HEADER:
if (!skb_mac_header_was_set(skb))
goto err;
if (skb_vlan_tag_present(skb)) {
if (!nft_payload_copy_vlan(dest, skb,
priv->offset, priv->len))
goto err;
return;
}
The nft_payload_copy_vlan function is called with two user-controlled parameters: priv->offset and priv->len. Remember that nft_payload’s purpose is to copy data from a particular layer header (IP, TCP, UDP, 802.11…) to an arbitrary register, and the user gets to specify the offset inside the header to copy data from, as well as the size of the copied chunk.
The following code snippet illustrates how to copy the destination address from the IP header to register 0 and compare it against a known value:
int create_filter_chain_rule(struct mnl_socket* nl, char* table_name, char* chain_name, uint16_t family, uint64_t* handle, int* seq)
{
struct nftnl_rule* r = build_rule(table_name, chain_name, family, handle);
in_addr_t d_addr;
d_addr = inet_addr("192.168.123.123");
rule_add_payload(r, NFT_PAYLOAD_NETWORK_HEADER, offsetof(struct iphdr, daddr), sizeof d_addr, NFT_REG32_00);
rule_add_cmp(r, NFT_CMP_EQ, NFT_REG32_00, &d_addr, sizeof d_addr);
rule_add_immediate_verdict(r, NFT_GOTO, "next_chain");
return send_batch_request(
nl,
NFT_MSG_NEWRULE | (NFT_TYPE_RULE << 8),
NLM_F_CREATE, family, (void**)&r, seq,
NULL
);
}
All definitions for the rule_* functions can be found in my Github project.
When I looked at the code under nft_payload_copy_vlan, a frequent C programming pattern caught my eye:
/* net/netfilter/nft_payload.c */ if (offset + len > VLAN_ETH_HLEN + vlan_hlen) ethlen -= offset + len - VLAN_ETH_HLEN + vlan_hlen; memcpy(dst_u8, vlanh + offset - vlan_hlen, ethlen);
These lines determine the size of a memcpy call based on a fairly extended arithmetic operation. I later found out their purpose was to align the skb pointer to the maximum allowed offset, which is the end of the second VLAN tag (at most 2 tags are allowed). VLAN encapsulation is a common technique used by providers to separate customers inside the provider’s network and to transparently route their traffic.
At first I thought I could cause an overflow in the conditional statement, but then I realized that the offset + len expression was being promoted to a uint32_t from uint8_t, making it impossible to reach MAX_INT with 8-bit values:
<+396>: mov r11d,DWORD PTR [rbp-0x64] <+400>: mov r10d,DWORD PTR [rbp-0x6c]
gef➤ x/wx $rbp-0x64 0xffffc90000003a0c: 0x00000004 gef➤ x/wx $rbp-0x6c 0xffffc90000003a04: 0x00000013
The compiler treats the two operands as DWORD PTR, hence 32 bits.
After this first disappointment, I started wandering elsewhere, until I came back to the same spot to double check that piece of code which kept looking suspicious.
On the next line, when assigning the ethlen variable, I noticed that the VLAN header length (4 bytes) vlan_hlen was being subtracted from ethlen instead of being added to restore the alignment with the second VLAN tag.
By trying all possible offset and len pairs, I could confirm that some of them were actually causing ethlen to underflow, wrapping it back to UINT8_MAX.
With a vulnerability at hand, I documented my findings and promptly sent them to security@kernel.org and the involved distros.
I also accidentally alerted some public mailing lists such as syzbot’s, which caused a small dispute to decide whether the issue should have been made public immediately via oss-security or not. In the end we managed to release the official patch for the stable tree in a day or two and proceeded with the disclosure process.
How an Out-Of-Bounds Copy Vulnerability works:
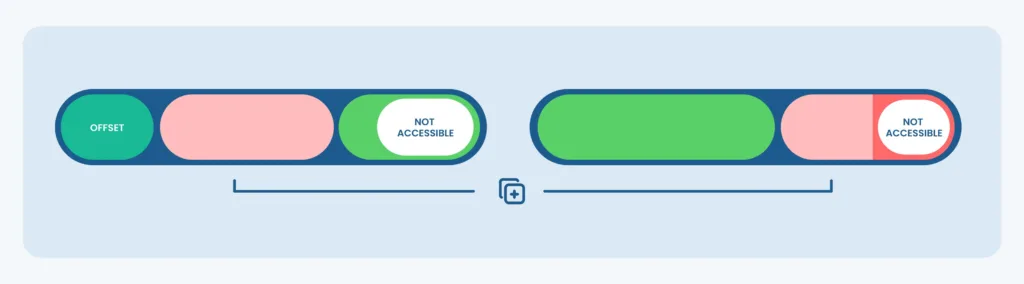
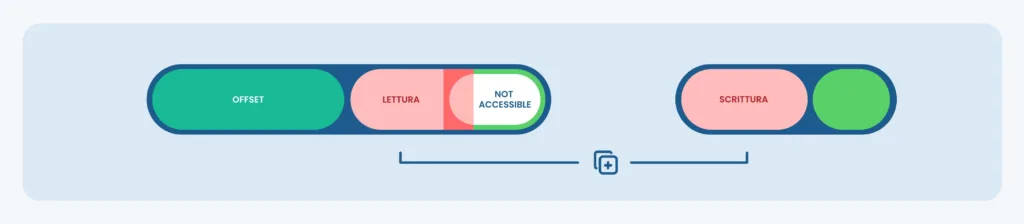
The behavior of CVE-2023-0179:

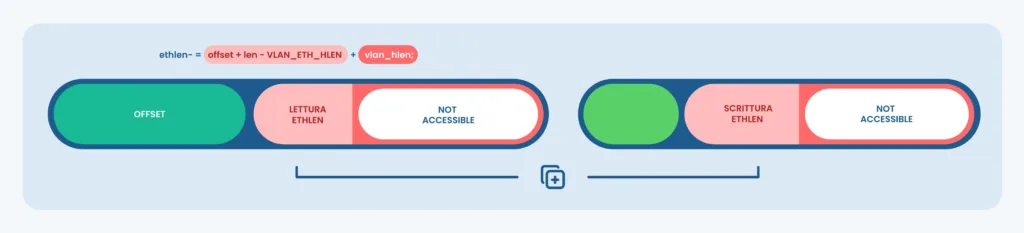
4. Reaching the code path
Even the most powerful vulnerability is useless unless it can be triggered, even in a probabilistic manner; here, we’re inside the evaluation function for the nft_payload expression, which led me to believe that if the code branch was there, then it must be reachable in some way (of course this isn’t always the case).
I’ve already shown how to setup the vulnerable rule, we just have to choose an overflowing offset/length pair like so:
uint8_t offset = 19, len = 4; struct nftnl_rule* r = build_rule(table_name, chain_name, family, handle); rule_add_payload(r, NFT_PAYLOAD_LL_HEADER, offset, len, NFT_REG32_00);
Once the rule is in place, we have to force its evaluation by generating some traffic, unfortunately normal traffic won’t pass through the nft_payload_copy_vlan function, only VLAN-tagged packets will.
4.1 Debugging nftables
From here on, gdb’s assistance proved to be crucial to trace the network paths for input packets.
I chose to spin up a QEMU instance with debugging support, since it’s really easy to feed it your own kernel image and rootfs, and then attach gdb from the host.
When booting from QEMU, it will be more practical to have the kernel modules you need automatically loaded:
# not all configs are required for this bug CONFIG_VLAN_8021Q=y CONFIG_VETH=y CONFIG_BRIDGE=y CONFIG_BRIDGE_NETFILTER=y CONFIG_NF_TABLES=y CONFIG_NF_TABLES_INET=y CONFIG_NF_TABLES_NETDEV=y CONFIG_NF_TABLES_IPV4=y CONFIG_NF_TABLES_ARP=y CONFIG_NF_TABLES_BRIDGE=y CONFIG_USER_NS=y CONFIG_CMDLINE_BOOL=y CONFIG_CMDLINE="net.ifnames=0"
As for the initial root file system, one with the essential networking utilities can be built for x86_64 (openssh, bridge-utils, nft) by following this guide. Alternatively, syzkaller provides the create-image.sh script which automates the process.
Once everything is ready, QEMU can be run with custom options, for instance:
qemu-system-x86_64 -kernel linuxk/linux-6.1.6/vmlinux -drive format=raw,file=linuxk/buildroot/output/images/rootfs.ext4,if=virtio -nographic -append "root=/dev/vda console=ttyS0" -net nic,model=e1000 -net user,hostfwd=tcp::10022-:22,hostfwd=udp::5556-:1337
This setup allows communicating with the emulated OS via SSH on ports 10022:22 and via UDP on ports 5556:1337. Notice how the host and the emulated NIC are connected indirectly via a virtual hub and aren’t placed on the same segment.
After booting the kernel up, the remote debugger is accessible on local port 1234, hence we can set the required breakpoints:
turtlearm@turtlelinux:~/linuxk/old/linux-6.1.6$ gdb vmlinux GNU gdb (Ubuntu 12.1-0ubuntu1~22.04) 12.1 ... 88 commands loaded and 5 functions added for GDB 12.1 in 0.01ms using Python engine 3.10 Reading symbols from vmlinux... gef➤ target remote :1234 Remote debugging using :1234 (remote) gef➤ info b Num Type Disp Enb Address What 1 breakpoint keep y 0xffffffff81c47d50 in nft_payload_eval at net/netfilter/nft_payload.c:133 2 breakpoint keep y 0xffffffff81c47ebf in nft_payload_copy_vlan at net/netfilter/nft_payload.c:64
Now, hitting breakpoint 2 will confirm that we successfully entered the vulnerable path.
4.2 Main issues
How can I send a packet which definitely enters the correct path? Answering this question was more troublesome than expected.
UDP is definitely easier to handle than TCP, a UDP socket (SOCK_DGRAM) wouldn’t let me add a VLAN header (layer 2), but using a raw socket was out of the question as it would bypass the network stack including the NFT hooks.
Instead of crafting my own packets, I just tried configuring a VLAN interface on the ethernet device eth0:
ip link add link eth0 name vlan.10 type vlan id 10 ip addr add 192.168.10.137/24 dev vlan.10 ip link set vlan.10 up
With these commands I could bind a UDP socket to the vlan.10 interface and hope that I would detect VLAN tagged packets leaving through eth0. Of course, that wasn’t the case because the new interface wasn’t holding the necessary routes, and only ARP requests were being produced whatsoever.
Another attempt involved replicating the physical use case of encapsulated VLANs (Q-in-Q) but in my local network to see what I would receive on the destination host.
Surprisingly, after setting up the same VLAN and subnet on both machines, I managed to emit VLAN-tagged packets from the source host but, no matter how many tags I embedded, they were all being stripped out from the datagram when reaching the destination interface.
This behavior is due to Linux acting as a router. Since a VLAN ends when a router is met, being a level 2 protocol, it would be useless for Netfilter to process those tags.
Going back to the kernel source, I was able to spot the exact point where the tag was being stripped out during a process called VLAN offloading, where the NIC driver removes the tag and forwards traffic to the networking stack.
The __netif_receive_skb_core function takes the previously crafted skb and delivers it to the upper protocol layers by calling deliver_skb.
802.1q packets are subject to VLAN offloading here:
/* net/core/dev.c */
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
...
if (eth_type_vlan(skb->protocol)) {
skb = skb_vlan_untag(skb);
if (unlikely(!skb))
goto out;
}
...
}
skb_vlan_untag also sets the vlan_tci, vlan_proto, and vlan_present fields of the skb so that the network stack can later fetch the VLAN information if needed.
The function then calls all tap handlers like the protocol sniffers that are listed inside the ptype_all list and finally enters another branch that deals with VLAN packets:
/* net/core/dev.c */
if (skb_vlan_tag_present(skb)) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
if (vlan_do_receive(&skb)) {
goto another_round;
}
else if (unlikely(!skb))
goto out;
}
The main actor here is vlan_do_receive that actually delivers the 802.1q packet to the appropriate VLAN port. If it finds the appropriate interface, the vlan_present field is reset and another round of __netif_receive_skb_core is performed, this time as an untagged packet with the new device interface.
However, these 3 lines got me curious because they allowed skipping the vlan_present reset part and going straight to the IP receive handlers with the 802.1q packet, which is what I needed to reach the nft hooks:
/* net/8021q/vlan_core.c */ vlan_dev = vlan_find_dev(skb->dev, vlan_proto, vlan_id); if (!vlan_dev) // if it cannot find vlan dev, go back to netif_receive_skb_core and don't untag return false; ... __vlan_hwaccel_clear_tag(skb); // unset vlan_present flag, making skb_vlan_tag_present false
Remember that the vulnerable code path requires vlan_present to be set (from skb_vlan_tag_present(skb)), so if I sent a packet from a VLAN-aware interface to a VLAN-unaware interface, vlan_do_receive would return false without unsetting the present flag, and that would be perfect in theory.
One more problem arose at this point: the nft_payload_copy_vlan function requires the skb protocol to be either ETH_P_8021AD or ETH_P_8021Q, otherwise vlan_hlen won’t be assigned and the code path won’t be taken:
/* net/netfilter/nft_payload.c */
static bool nft_payload_copy_vlan(u32 *d, const struct sk_buff *skb, u8 offset, u8 len)
{
...
if ((skb->protocol == htons(ETH_P_8021AD) ||
skb->protocol == htons(ETH_P_8021Q)) &&
offset >= VLAN_ETH_HLEN && offset < VLAN_ETH_HLEN + VLAN_HLEN)
vlan_hlen += VLAN_HLEN;
Unfortunately, skb_vlan_untag will also reset the inner protocol, making this branch impossible to enter, in the end this path turned out to be rabbit hole.
While thinking about a different approach I remembered that, since VLAN is a layer 2 protocol, I should have probably turned Ubuntu into a bridge and saved the NFT rules inside the NFPROTO_BRIDGE hooks.
To achieve that, a way to merge the features of a bridge and a VLAN device was needed, enter VLAN filtering!
This feature was introduced in Linux kernel 3.8 and allows using different subnets with multiple guests on a virtualization server (KVM/QEMU) without manually creating VLAN interfaces but only using one bridge.
After creating the bridge, I had to enter promiscuous mode to always reach the NF_BR_LOCAL_IN bridge hook:
/* net/bridge/br_input.c */
static int br_pass_frame_up(struct sk_buff *skb) {
...
/* Bridge is just like any other port. Make sure the
* packet is allowed except in promisc mode when someone
* may be running packet capture.
*/
if (!(brdev->flags & IFF_PROMISC) &&
!br_allowed_egress(vg, skb)) {
kfree_skb(skb);
return NET_RX_DROP;
}
...
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN,
dev_net(indev), NULL, skb, indev, NULL,
br_netif_receive_skb);
and finally enable VLAN filtering to enter the br_handle_vlan function (/net/bridge/br_vlan.c) and avoid any __vlan_hwaccel_clear_tag call inside the bridge module.
sudo ip link set br0 type bridge vlan_filtering 1 sudo ip link set br0 promisc on
While this configuration seemed to work at first, it became unstable after a very short time, since when vlan_filtering kicked in I stopped receiving traffic.
All previous attempts weren’t nearly as reliable as I needed them to be in order to proceed to the exploitation stage. Nevertheless, I learned a lot about the networking stack and the Netfilter implementation.
4.3 The Netfilter Holy Grail
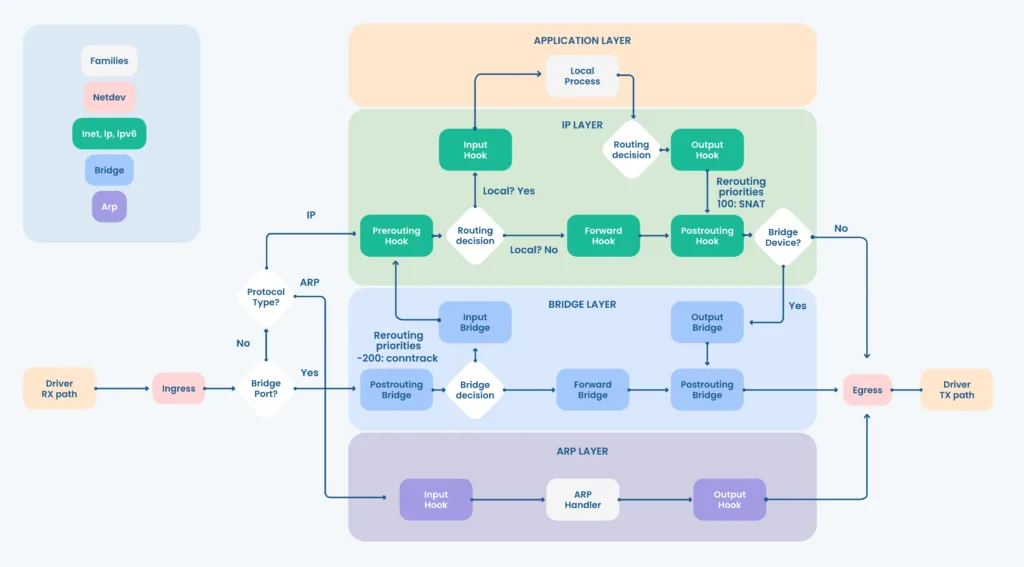
While I could’ve continued looking for ways to stabilize VLAN filtering, I opted for a handier way to trigger the bug.
This chart was taken from the nftables wiki and represents all possible packet flows for each family. The netdev family is of particular interest since its hooks are located at the very beginning, in the Ingress hook.
According to this article the netdev family is attached to a single network interface and sees all network traffic (L2+L3+ARP).
Going back to __netif_receive_skb_core I noticed how the ingress handler was called before vlan_do_receive (which removes the vlan_present flag), meaning that if I could register a NFT hook there, it would have full visibility over the VLAN information:
/* net/core/dev.c */
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev) {
...
#ifdef CONFIG_NET_INGRESS
...
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0) // insert hook here
goto out;
#endif
...
if (skb_vlan_tag_present(skb)) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
if (vlan_do_receive(&skb)) // delete vlan info
goto another_round;
else if (unlikely(!skb))
goto out;
}
...
The convenient part is that you don’t even have to receive the actual packets to trigger such hooks because in normal network conditions you will always(?) get the respective ARP requests on broadcast, also carrying the same VLAN tag!
Here’s how to create a base chain belonging to the netdev family:
struct nftnl_chain* c;
c = nftnl_chain_alloc();
nftnl_chain_set_str(c, NFTNL_CHAIN_NAME, chain_name);
nftnl_chain_set_str(c, NFTNL_CHAIN_TABLE, table_name);
if (dev_name)
nftnl_chain_set_str(c, NFTNL_CHAIN_DEV, dev_name); // set device name
if (base_param) { // set ingress hook number and max priority
nftnl_chain_set_u32(c, NFTNL_CHAIN_HOOKNUM, NF_NETDEV_INGRESS);
nftnl_chain_set_u32(c, NFTNL_CHAIN_PRIO, INT_MIN);
}
And that’s it, you can now send random traffic from a VLAN-aware interface to the chosen network device and the ARP requests will trigger the vulnerable code path.
Continue reading: 64 bytes and a ROP chain – A journey through nftables – Part 2



Scopri come possiamo aiutarti
Troviamo insieme le soluzioni più adatte per affrontare le sfide che ogni giorno la tua impresa è chiamata ad affrontare.